So, this is a series that I imagine will continue for… ever. But it will definitely be something that pops up a lot in the early post-school years. And would have popped up a lot during school if I had thought to approach it this way at the time. But I didn’t. Yet another way in which I have no clue what I’m doing. Haha? But, in all seriousness, the idea of this post (and the many that will follow) will be to illustrate how things that I thought to be correct or good ideas earlier in the blog turned out to be very bad ideas after implementation and thorough testing and iteration happened. Who would have guessed that I wasn’t going to get everything right the first time always? …Everyone.
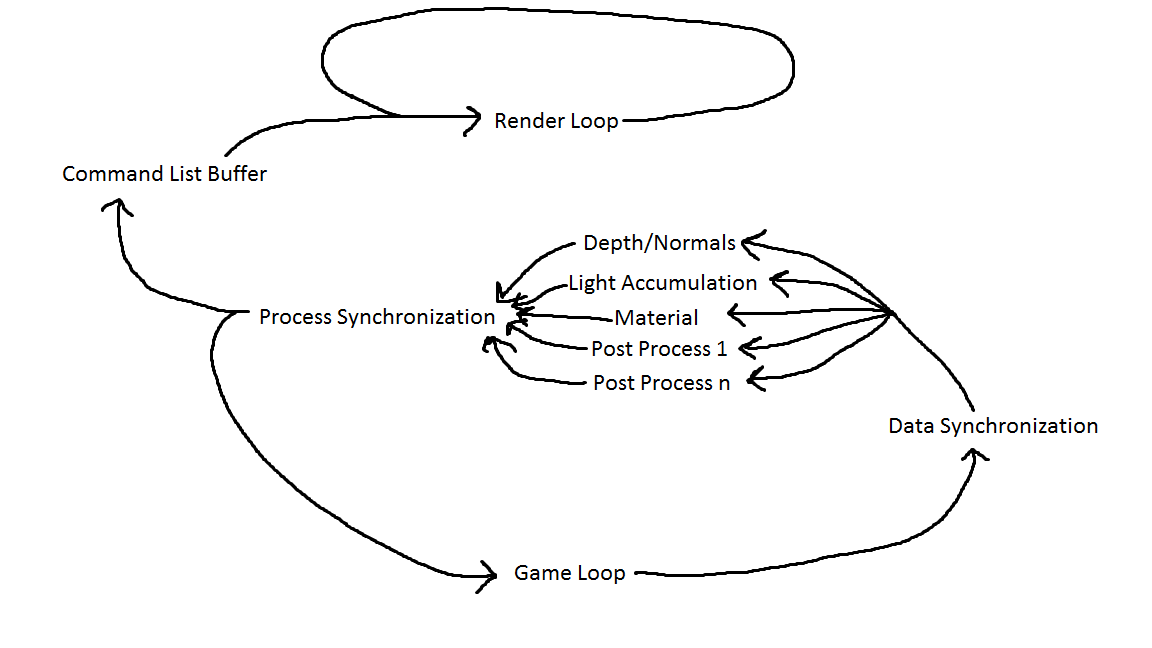
This first entry in the series is in regards to my entity transfer buffer, and my general threading model considerations, as described in a blog post from earlier this year. In it, I devoted a bit of code to solving concurrency concerns as they related to updating renderable data from the core engine into my rendering library and to maintaining data that might be getting rendered after the core tried to delete it. To the second point, more experience with how DirectX 11 command buffers store “in-flight” data quickly made it clear that I didn’t need to handle this at all. To the first point, the code presented didn’t even fully solve the problem it was trying to address (the way I was buffering add/remove/update commands into the container still had data race issues), plus it introduced a memory leak in the buffered update, and in general presented a terrible calling convention where I expected the external caller to allocate a data struct that I would internally delete. Just… truly horrific stuff. But, on top of all of that, I’ve come to realize that a lot of this code was written to solve a problem I shouldn’t be trying to deal with in the first place.
Our engine was built as a synchronous core with potentially asynchronous systems. At least for this project, attempting to write a thread-safe interface into my rendering library was absolutely overkill since there weren’t any threading related issue with transferring data from the core into my library. By making my code only as complicated as it needed to be, rather than as complicated as it could be, I made it a lot more stable and functional. Of course, this opens up another line of questioning; if I wanted to clean up my code and make my library publicly available, wouldn’t it be smart to have a thread-safe interface? And to that, I’d say… maybe. It might be nice, but unless you’re making a truly professional grade, absolutely everything must perform at maximum performance, tip top engine, I’m not sure that making the core architecture asynchronous is a great idea. For smaller scale engines like the one that we built this year, it makes a lot more sense to keep the core simple and let each system handle it’s own threading as it sees fit. You still get a lot of good performance and generally decent scalability this way, without all of the headache and hassle of managing an entire engine’s worth of thread ordering, syncing, etc.
In the end, this is what my TransferBuffer class ended up being:
template <typename t_entry, typename t_data, typename t_id>
class TransferBuffer
{
typedef typename std::unordered_map<t_id, t_entry>::iterator t_iterator;
private:
std::unordered_map<t_id, t_entry> m_entries;
t_id m_nextID;
public:
TransferBuffer() {
m_nextID = 0;
}
~TransferBuffer() {
}
//This should only ever be called by the game engine!
t_id AddEntry(t_data pData) {
t_id lReturnID = m_nextID++;
t_entry lEntry = pData->CreateEntity();
m_entries.emplace(lReturnID, lEntry);
return lReturnID;
}
//This should only ever be called by the game engine!
void RemoveEntry(t_id pID) {
auto lIter = m_entries.find(pID);
if (lIter != m_entries.end())
{
t_entry lEntry = lIter->second;
delete lEntry;
m_entries.erase(lIter);
}
}
//This should only ever be called by the game engine!
void UpdateEntry(t_id pID, t_data pData) {
auto lIter = m_entries.find(pID);
if (lIter != m_entries.end())
{
lIter->second->UpdateData(pData);
}
}
//This should only ever be called by parallel producer threads!
t_iterator GetEntries() {
return m_entries.begin();
}
t_iterator GetEnd() {
return m_entries.end();
}
//This should only be called from the interface to expose mesh data for physics!
t_entry GetFromID(t_id pID) {
auto lIter = m_entries.find(pID);
t_entry lEntry = nullptr;
if (lIter != m_entries.end())
{
lEntry = lIter->second;
}
return lEntry;
}
};
And then, of course, this class didn’t really need to be a template at all. Since all entity and entitydata objects inherit from the same base IEntity and EntityData types, I was able to make an array of TransferBuffer<IEntity*, EntityData*, unsigned> to store my various entity types. And this allowed me to remove gross switch statements from each operation that my entity manager had to perform, instead accessing the array based on an enum that defined index by entity type. So, in the end, a lot less code, a lot more stability, and nothing really lost in the translation.
And, that’s it for the first installment of me being incredibly wrong about things. In other news, I gave a talk about my actual, finished multi-threaded rendering system at Game Engine Architecture Club last month, so once that video gets uploaded to YouTube expect a post about it with links to my slides. Also, I recently got into the Heroes of the Storm tech alpha and was delighted to see features that I wrote last summer in heavy use in the game (!!!), so also expect a post about that in the very near future. Stay tuned for those updates; otherwise, it’s the final push through finals and into graduation, followed by plenty of sleep!